
Want to learn more? Book a presentation with our team
In the past few years, QSAR modelling powered by neural networks have gained popularity. This is due to their ability to capture intricate and non-linear relationships in chemical data. Although they often require a complex parameterisation, these models have proven to be the most powerful and versatile algorithms for handling this type of problem.
QUEEN is designed to break down this complexity.
Learn more about FAST and the whole ALChemy Suite

Want to learn more? Book a presentation with our team
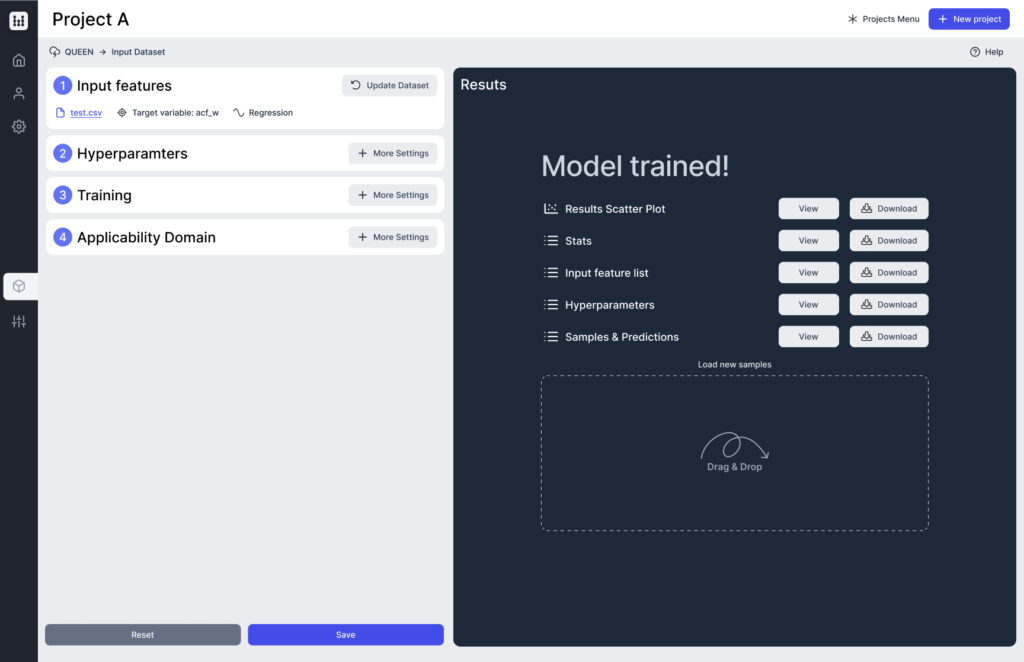
QUEEN gathers any phase of the QSAR modelling process powered by neural networks, with a simple and intuitive interface. It incorporates, indeed, a fully automated hyperparameters optimisation algorithm based on Bayesian method and, once trained on the final model, the possibility to merge hundreds of individual models in a single response.
Finally, this approach guarantees robust and performing results in any conditions while keeping a simple and almost parameter-free setup.
The minimum information required to effectively use this software is a dataset including the following components: Target Variable and Matrix of Molecular Descriptors. Anytime QUEEN is executed in line with FAST, all the previous information is automatically taken from the FAST output.
If no training/test labels are present within the dataset, QUEEN can handle the splitting by applying one of the two different approaches currently implemented: Random splitting and Venetian blind (default).
Optimisation of the hyperparameters of the neural network model via a Bayesian Algorithm. If fixed parameters are already defined, the step can be skipped.
Several replicas which differ for the initial random weights are trained. For each of them, a loss value is calculated on the calibration samples in terms of mean squared error and categorical cross entropy for regression and classification tasks respectively. The replica that exhibits the best predictive performance is chosen as the final model
Each prediction comes with an applicability domain (AD) score and label that indicates the reliability of the model outcome for the given sample.
With the files obtained (either log files or export files), it is possible to re-upload the fully trained machine learning model. The export file that has been produced at the end of the training process can be re-opened by QUEEN and used to predict the target property on any new sample.
Learn more about the whole Suite ALChemy

Questions about our products?
Drop us a few lines via email!