
Vuoi saperne di più? Prenota una presentazione con il nostro team
FAST, uno strumento basato sull’approccio full-search per eseguire rapidamente la selezione delle caratteristiche, è il primo software di una suite progettata per guidare chimici computazionali, laboratori e aziende lungo l’intero processo di modellazione QSAR
Scopri di più su QUEEN e l’intera Suite ALChemy

Vuoi saperne di più? Prenota una presentazione con il nostro team
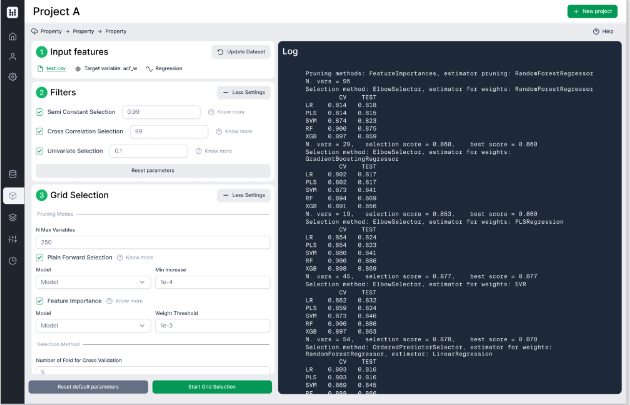
Durante la creazione di un modello di machine learning, l’identificazione di un sottoinsieme appropriato di features gioca un ruolo cruciale. Nella modellazione QSAR, in cui la quantità di descrittori molecolari disponibili nel dataset iniziale è enorme, questo passaggio è quello che influenza maggiormente le prestazioni finali. Poiché in letteratura non è stato individuato un criterio per determinare a priori l’approccio migliore tra i tanti disponibili, abbiamo sviluppato uno strumento che ne utilizza sistematicamente molti e sceglie quello che, caso per caso, mostra la migliore performance
FAST è il primo strumento della suite che Kode Chemoinformatics ha sviluppato sviluppando per supportare chimici computazionali, laboratori e organizzazioni nei settori chimico, farmaceutico, alimentare e delle biotecnologie. Il cliente viene quindi guidato attraverso l’intero processo di creazione, gestione e implementazione dei modelli QSAR, dalla selezione delle caratteristiche alla predizione.
Al fine di garantire il miglior sottoinsieme di features, minimizzando l’errore previsionale, FAST affronta la Featiires Selection attraverso tre passaggi sequenziali. Ogni passaggio ha costo computazionale e rigore crescenti, riducendo progressivamente la dimensione del dataset. L’approccio sequenziale consente di concentrare lo sforzo computazionale di ogni passaggio su un adeguato set di dati, rendendo il nuovo dataset accessibile per il passaggio successivo. Il tempo risparmiato consente di testare un gran numero di soluzioni diverse anche su un normale laptop. Infine, FAST calcola la qualità di ciascun set in termini di prestazioni delle previsioni attraverso uno o più modelli di machine learning.

FAST identifica un insieme di soluzioni. Ciascuna di esse è accompagnata da un indice di Accuracy, che permette di determinare quale set funziona meglio. Questo risultato si ottiene con un metodo in tre fasi
Rimozione di quelle features che sono ridondanti o che presentano caratteristiche non compatibili con la modellazione
Rimozione di tutte le caratteristiche con importanza bassa o insufficiente all’interno dei modelli
Selezione di features, con convalida incrociata, che garantiscono il compromesso ottimale tra bias e varianza
Hai domande sui nostri prodotti?
Scrivici via email!