
Vuoi saperne di più? Prenota una presentazione con il nostro team
Negli ultimi anni, la modellazione QSAR basata su reti neurali ha riscontrato crescente popolarità, grazie alla sua capacità di catturare relazioni complesse e non lineari nei dati chimici. Questi modelli hanno infatti dimostrato di essere gli algoritmi più potenti e versatili per gestire questo tipo di problemi, sebbene richiedano spesso una parametrizzazione complessa.
QUEEN è progettata per abbattere proprio questa complessità.
Scopri di più su FAST e sull’intera Suite ALChemy

Vuoi saperne di più? Prenota una presentazione con il nostro team
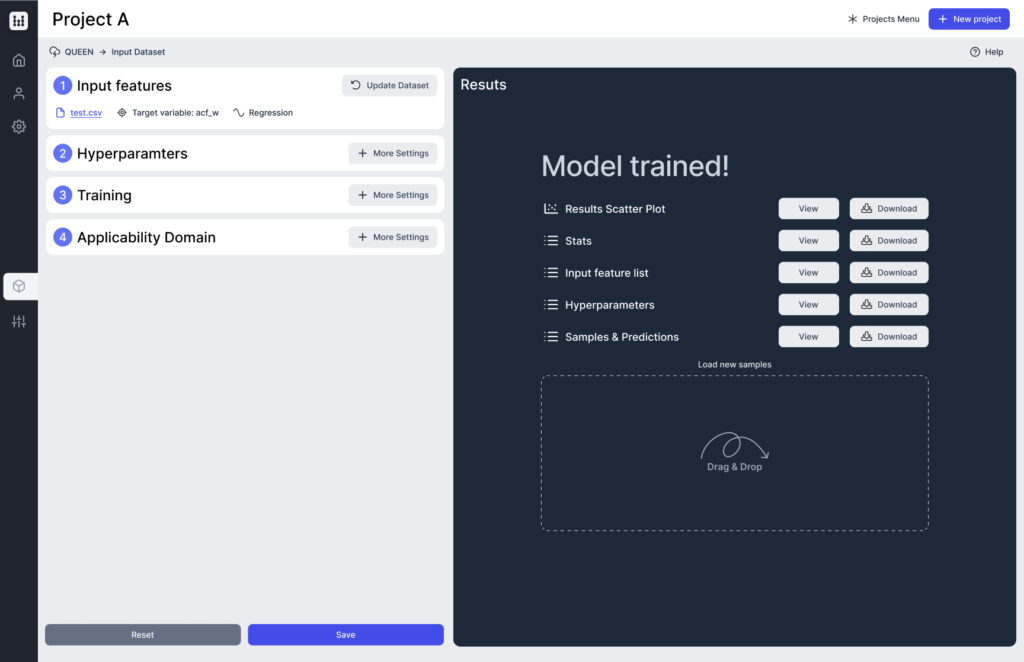
QUEEN riunisce tutte le fasi del processo di modellazione QSAR basate su reti neurali in un’interfaccia semplice e intuitiva. Incorpora, infatti, un algoritmo di ottimizzazione degli iperparametri completamente automatizzato basato sul metodo Bayesiano e, una volta addestrato sul modello finale, la possibilità di unire centinaia di modelli individuali in un’unica risposta.
Questo approccio garantisce risultati robusti e performanti in qualsiasi condizione, pur mantenendo una configurazione semplice e quasi priva di parametri.
Le informazioni minime per utilizzare in efficacemente questo software consistono in un dataset con le seguenti componenti: variabile target e matrice dei descrittori molecolari. Ogni volta che QUEEN viene eseguito in linea con FAST, tutte le informazioni vengono automaticamente prese dall’output di FAST.
Se nel dataset non sono presenti etichette training/test, QUEEN può gestire la suddivisione applicando uno dei due approcci attualmente implementati: Random splitting and Venetian blind (impostazione predefinita).
Ottimizzazione degli iperparametri del modello di rete neurale tramite un algoritmo Bayesiano. Se i parametri fissi sono già definiti, il passaggio può essere saltato.
Vengono addestrate diverse repliche che differiscono per i pesi casuali iniziali. Per ciascuna di esse, viene calcolato un valore di loss sui campioni di calibrazione in termini di errore quadratico medio e categorical-cross-entropy rispettivamente per la regressione e la classificazione. La replica che presenta le migliori prestazioni predittive viene scelta come modello finale.
Ogni predizione viene fornita con un punteggio e un’etichetta di Applicability Domain (AD) che indica l’affidabilità del risultato del modello per il campione fornito.
Con i file ottenuti (file di log o file di esportazione), è possibile ricaricare il modello addestrato di Machine Learning. Il file di esportazione prodotto al termine del processo di training può essere riaperto da QUEEN e utilizzato per prevedere la proprietà target su qualsiasi nuovo campione.
Scopri di più sull’intera Suite ALChemy

Hai domande sui nostri prodotti?
Scrivici via mail!